
Motivation:
The ultimate goal of this project is to build a searchable database model (potentially on Google Cloud) and access via the lairhub website. During this process, a key challenge might be ensuring that the database not only supports complex queries but also integrates visual data representations, enhancing the value and comprehensibility of the information presented. This could be potentially addressed through careful software design and community feedback, ensuring that the features and functionalities meet the specific needs of researchers and scholars in these fields.
Research Questions
- How can we design and build a structured data model that supports efficient data retrieval and search functionalities, focusing on enhancing findability?
- How can we design and develop customizable visualization tools that satisfy specific needs of humanities and social science researchers, enabling them to visually analyze and interpret complex datasets effectively?
- What interactive features can be integrated into our platform to foster meaningful discussions among users and encourage collaborative research?
- How to directly link datasets to published research articles and papers from our database, providing a seamless connection between data and their output?
Problem Definition:
The DCDATA Info project, dedicated to support research in humanities and social sciences, aims to address critical challenges in data accessibility and usability by refining the data model for enhanced organization and retrieval capabilities. The development of visualization tools and secure web interfaces is also crucial, and these improvements will enable more intuitive navigation and robust data interaction, enhancing the platform’s effectiveness for academic research.
Potential Findings:
The project anticipates the development of advanced data models focused on enhancing findability. This includes implementing sophisticated visualization tools that not only engage users but also make it easier to locate and understand data. The user interfaces will be refined to offer more precise and efficient search capabilities. These improvements are expected to accelerate research activities and significantly increase the utility of the database for scholars.
Methodology:
Data collection and management: We need to first identify the types of data included in the database, such as datasets, images, or metadata related to research in the humanities and social sciences, and it is also important to specify the formats these data types will take (e.g., CSV, JSON, XML). In addition, we need to describe the sources from which data will be acquired. This could include academic publications, public data repositories or contributions from individual researchers. Then we will outline the methods for data collection, including web searching, APIs for existing data repositories or direct uploads by users. Finally, we should discuss the use of database management systems (DBMS) like MySQL and the implementation of data updates and backups.
Structured data model development: Utilize standards such as Dublin Core to create a preliminary database model that enhances data findability.
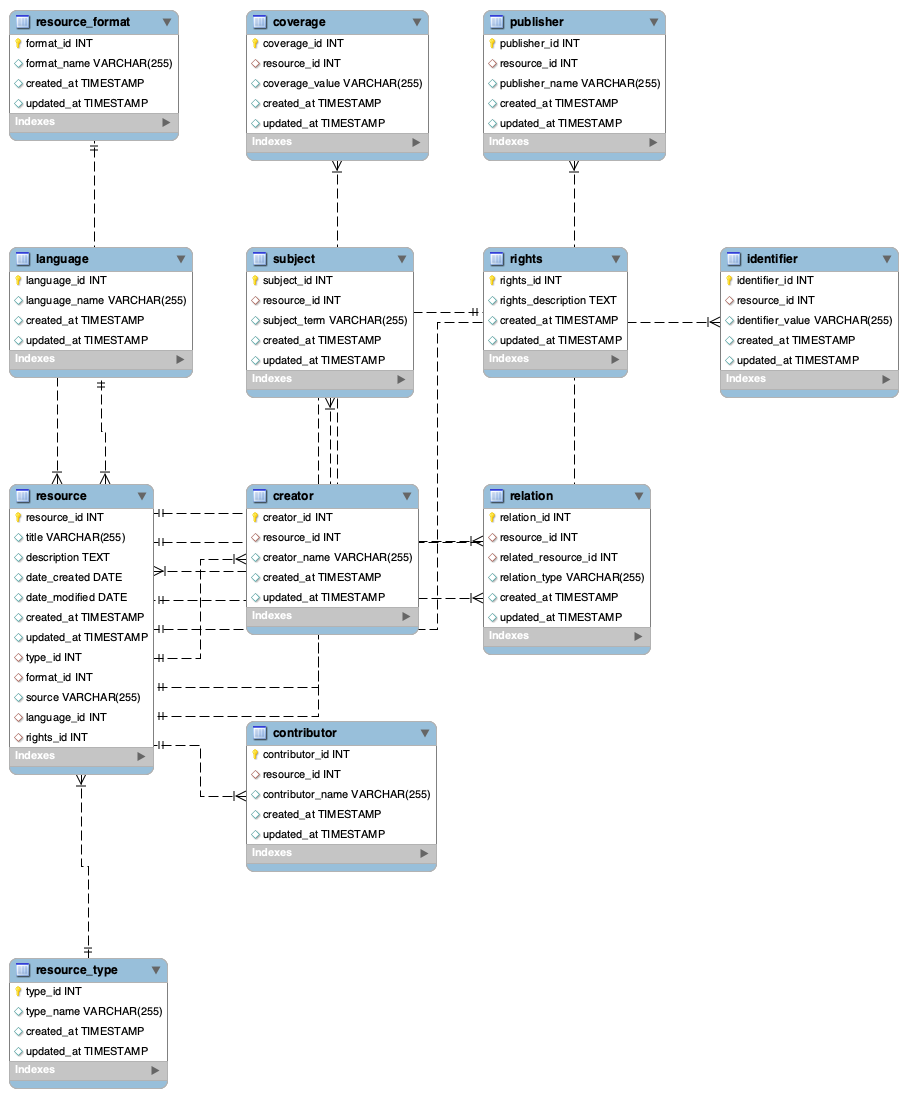
Building visualization tools: To develop visualization tools that allow users to derive meaningful insights from datasets, it will involve selecting appropriate software libraries such as D3.js, which support a wide range of visual representation types (e.g., graphs, heat maps, network diagrams).
Describing user interaction features: Enhancing user interaction on the platform involves implementing features that facilitate communication and collaboration among users.
Linking data to publications: Linking datasets directly to their corresponding research publications involves creating a system where each dataset can be tagged with DOIs and other bibliographic metadata that reference related publications.
Limitations and Future Work:
One significant limitation revolves around the findability of data within the database. Despite sophisticated data models and systems, the inherent complexity of data in humanities and social sciences can make it difficult to maintain efficient search capabilities that provide relevant and quick results. These challenges are augmented by the specialized needs of academic research, which often requires accessing obscure or highly specific data sets. The variability in data types, ranging from text documents to complex visual data, complicates the creation of a universally effective search mechanism. For instance, text-based data may be indexed effectively using traditional keyword searches, but this approach might not be as effective for visual or non-standard data formats, which may require more advanced image recognition techniques.
To address these challenges, we could explore more advanced machine learning algorithms for semantic search, which could improve the ability to interpret and retrieve complex datasets based on context rather than mere keywords. Moreover, integrating user feedback mechanisms to refine search algorithms continuously could also enhance findability. The literature in the field (Karimova et al, 2019) also highlights several approaches to improving data discoverability in academic databases, such as implementing enhanced metadata schemes, utilizing advanced search algorithm or enhancing community engagement and feedback.
Reference: Karimova, Y., Castro, J. A., & Ribeiro, C. (2019, January). Data deposit in a ckan repository: A dublin core-based simplified workflow. In Italian Research Conference on Digital Libraries (pp. 222-235). Cham: Springer International Publishing.